I recently got into a race condition situation when loading a node module that I use for configuration. This config file sets values differently depending on the environment. I was getting different environemnts in my code at the same time!
My strategy below is to set the environment variable first thing. Then, everything that looks up that environment variable (i.e. my config module) will be good to go! Easy right? Well…. not so much.
setup.js
1
2
3
4
5
6
process.env.NODE_ENV = 'test';
console.log('calling config from setup.js');
var config = require('../config/config');
var seeder = require('./seeder');
seeder.js
1
2
console.log('calling config from seeder.js');
var config = require('../config/config');
Here’s the output I was seeing:
1
2
calling config from seeder.js
calling config from setup.js
That’s backwards from what I expect. Now, to be fair, when I hit this script directly, it works as expected. However, when I require setup.js as a module, that’s when I see my issues.
Because the seeder.js script is running first, the environment remains unset. Because of this, there’s no certainly about my environment at any given time.
The workaround?
The workaround is to avoid the problem altogether. But it really is the best solution.
What we can do is launch the script with the environment set and then remove the setting of the environment within the code. Here’s how we can launch the script in an environment called “test”:
1
$ NODE_ENV=test mocha test
…where mocha could be node or any other executable.
To avoid writing this every time, we can use the npm’s script functionality. In our package.json file, we can add a line under an entry called scripts.
1
2
3
"scripts": {
"test": "NODE_ENV=test mocha test"
}
Now, when we run tests, we can run:
1
$ npm test
This is a great lesson why global variables should be avoided in node. I’ll give the main environment variable a pass though ;)
I recently dove into the land of Babel to take advantage of the latest and greatest that javascript has to offer. I’ve been using Babel as an interpreter on the client-side via jspm, which I’m a huge fan of. However, using it on the server side just seemed more difficult. But, it wasn’t too bad. Babel has instructions for a lot of setups and situations.
I’m using nodemon in dev and pm2 in production. There are instructions for nodemon, but not pm2, so that’s what I’m going to explain.
Install babel on your production server
1
$ npm install -g babel
That was easy. Now we can globally use babel-node instead of node to execute our es6+ code.
Tell pm2 to use babel
I first looked a this GH issue. There was a lot of confusion. All of the confusion revolves around what command line command to give. I’m using a JSON config file, so I thought I would just consult the JSON config file docs. There is an option called “exec_interpreter”. That looks pretty good. I’ll add that to my JSON file.
Here it is in context:
1
2
3
4
5
6
7
8
{
"name" : "myapp",
"script" : "/var/www/myapp/current/bin/www",
"exec_interpreter" : "babel-node",
"env": {
"NODE_ENV": "production"
}
}
Based on the confusion in the thread I wasn’t sure if that would work, but it did. You’ll have to to kill the old PM2 process and start up from the JSON file again.
One interesting side-effect was that my memory usage (that PM2 reports) dropped over 60%. I don’t know why, but I’m not complaining.
The first answer to that GH issue was to “use bable-node as the exec_interpreter” and that was 100% the answer. Perhaps this is a case of RTFM? I’m usually on the wrong side of that, so I’m glad it worked out!
I’m using Ubuntu 14.04 and Node 0.12.5. (A convenient digital ocean droplet!)
SSH into our machine….
Setup Nginx
Nginx is a web server. It routes and manages incoming connections. It serves the same purpose as Apache.
Install
1
2
sudo apt-get update
sudo apt-get install nginx
The main commands:
It will be started after install. These are for reference. You don’t need to do any of them right now.
1
2
3
sudo service nginx start
sudo service nginx stop
sudo service nginx restart
Getting familiar with nginx
Where is nginx?
1
cd/etc/nginx
If we looks at the directory listing (ls), we see all the goodies. At this point, all I really care about are two folders: sites-enabled and sites-available.
We need to put a record of our site in sites-available. Then, we’ll put a symbolic link to that file in sites-enabled. The records in sites-enabled are what nginx looks for when mapping incoming requests to the files to execute (our app!).
Make a record for our app in sites-available
I like to start by making a copy of the default record.
1
2
cd /etc/nginx/sites-available
cp default your.site.com
Tell nginx what we want to happen when we get a request to that URL
We do that by creaing a vhost file. You can use any shell text editor you want. I like pico because it tells me what to do. If you’re a cool person you’ll probably use vim.
1
pico your.site.com
You’ll see there’s a ton of comments. (# = comment). If you study this file it will explain a lot of great things. Otherwise, I just delete everything (Ctrl+K cuts a line at a time. I’m too lazy to learn the correct way to delete thing). So what was the purpose of copying? Yeah, I really just think it’s worthing looking at the possible options to get familiar with nginx.
So here’s what your file should look like:
1
2
3
4
5
6
7
8
9
10
11
12
13
server {
listen80;
server_name your.site.com;
location / {
proxy_pass http://127.0.0.1:3009;
proxy_http_version1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass$http_upgrade;
}
}
Two things you’ll need to change…. the server name on line 4. And the port at the end of line 61. Well, you don’t need to change the port, but it will need to match whatever port your launch your node app on.
So what’s going on here? Basically, this is known as a reverse proxy. When you run node on development on your computer you get a local address with a port. You visit that local address on that port and you see your site. This is the same thing. Nginx just acts as a gobetween from external users to the localhost on your server.
Enable the site
We enable the site by placing the same record we created in sites-available in sites-enabled. The best way to do this is with a symbolic link so that changes in one place are reflected in both locations.
Now that everything is setup, we need to restart Nginx
1
sudo service nginx restart
Run our app with PM2
You could start your app like you normally woul with the node command, adjusting the port as you normally would, but if you have one error, your app will crash.
PM2 is a service that automatically restarts your node app if it crashes. It does some other cool things too that make it better for production that something like nodemon.
I chose PM2 over Passenger because I couldn’t get Passenger to work. PM2 just works with very little config.
Install PM2
1
sudo npm install pm2 -g
Here is my go-to pm2 command:
1
pm2 list
That gives an overview of your processes.
Note: PM2 works on a per-user basis. I use PM2 from my deployer user since the deployer user has restricted permissions and needs to restart the app whenever there’s an update. I know I haven’t mentioned a deployer user yet. I’ll explain in another blog post
Configure PM2 to run our app
We can configure PM2 with a json file. This isn’t the only way, but I like it since I can set my environment to be production and do other cool things.
I’ve created a file called pm2-config.json in my app file home: /var/www/your.site.com. It doesn’t matter too much where you put the file.
Let’s create our config file:
1
2
cd /var/www/your.site.com
pico pm2-config.json
Here’s what my file looks like:
1
2
3
4
5
6
7
8
{
"name" : "myprocessname",
"script" : "current/bin/www",
"port" : 3009,
"env": {
"NODE_ENV": "production"
}
}
It’s pretty simple. You just need to change the valuse to match your needs. Script is the entry point of your app. I’m using the express framework, so the entry point to your app may look different.
Important Make sure the port setting matches what you said the port would be when you were configuring Nginx. It doesn’t matter if you have a different port setting in your script file. PM2 will override it.
Note: Why do I have “myprocessname” instead of “your.site.com”. Many of my apps use two processes. One to access the app in a traditional manner, and another to listen for messages from a message queue. I can restart these processes independently from eachother.
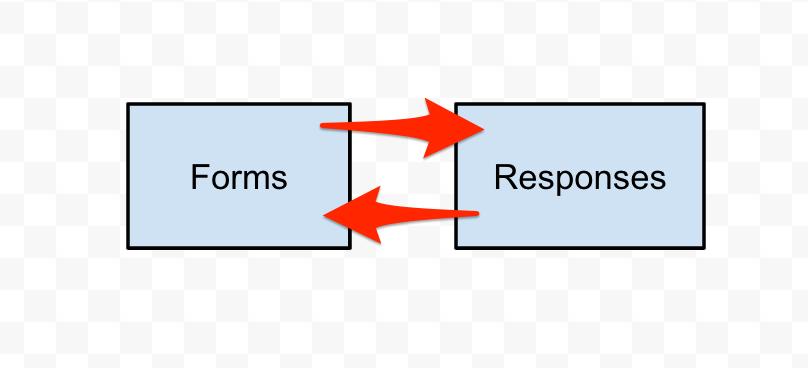
The undefined function is forms.getForm. This was odd because 1. forms clearly contained that function, and 2. That code passed my test suite. The “undefined is not a function” error was only happening when using the app.
As it turns out, the problem was a circular dependency. responses requires forms, but forms also requires responses. I had no idea you couldn’t do this. I agreed that it was a bit of a code smell to have a circular dependency like that, but it could be done right? Well, no.
The node docs explain this briefly, and explain that in order to prevent an infinite loop, an unfinished copy of the exported object can be returned. This is what I experienced. The forms variable was an empty object.
Solutions
Move the require statement to where it’s needed
The easiest solution is to move the require statement into the function that uses it. The above code would become:
To me that looks really ugly. What if you make a lot of use of that module? You’d have to include it in each function. Also, I like glancing at the top of a file and knowing what modules the file depends upon. This is possibly inefficient as well.
Or, change your architecture
Just remove the circular logic. Simple right? Here’s how I did it.
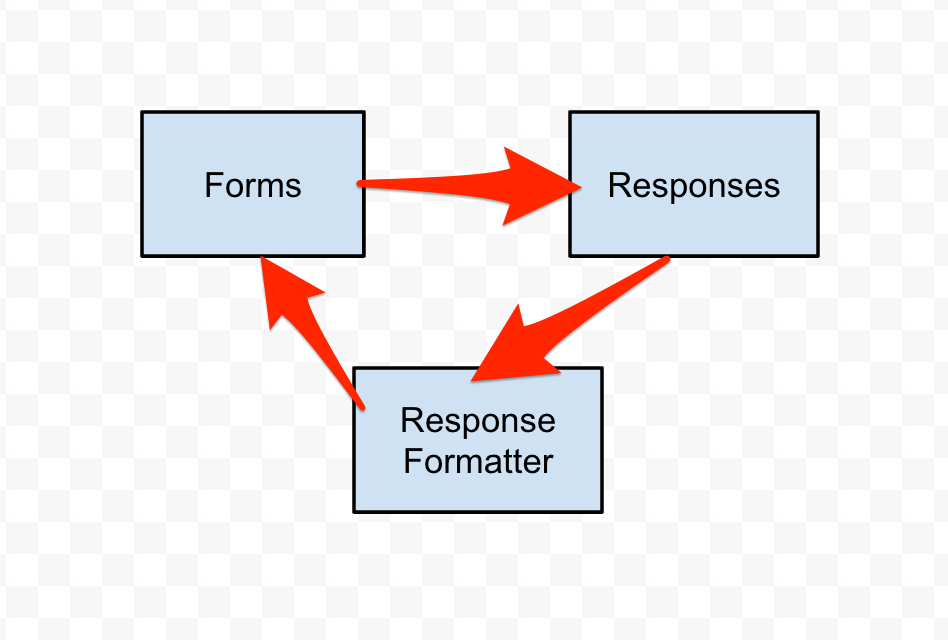
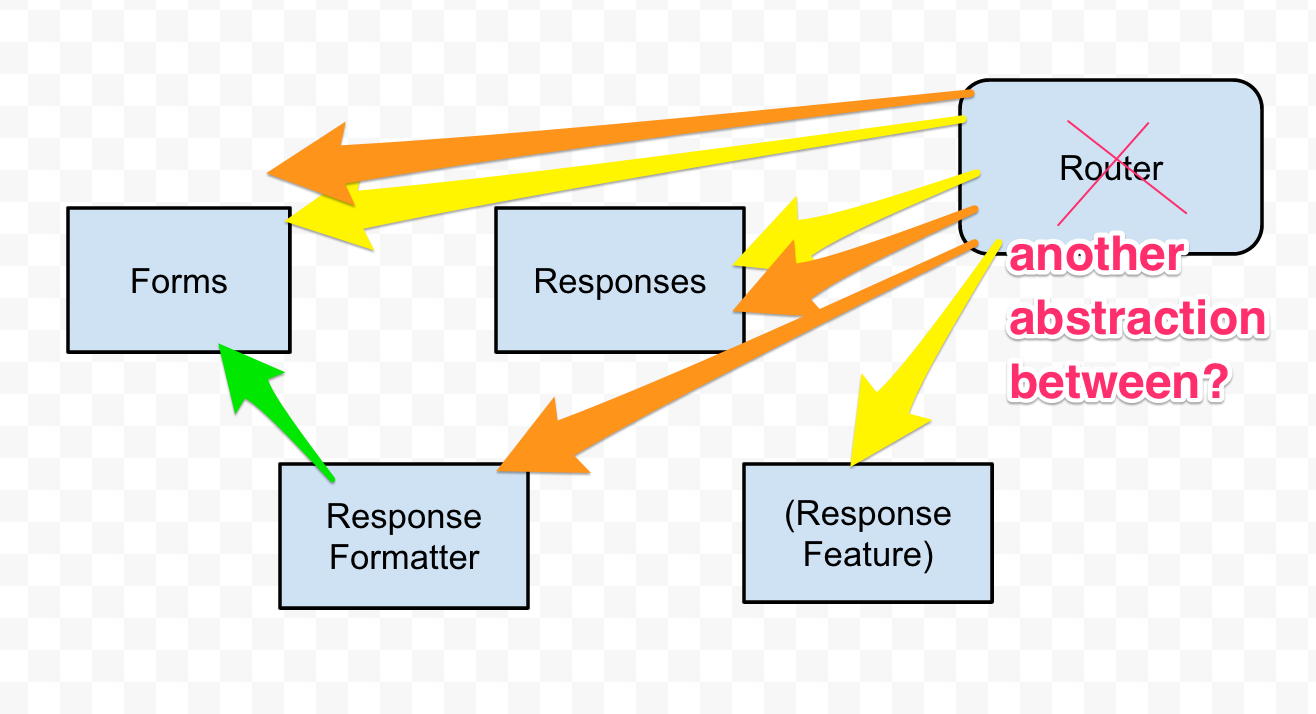
This clearly wasn’t going to fly. I decided to move my “formatting” logic out of responses. This makes sense. But here’s what I ended up with:
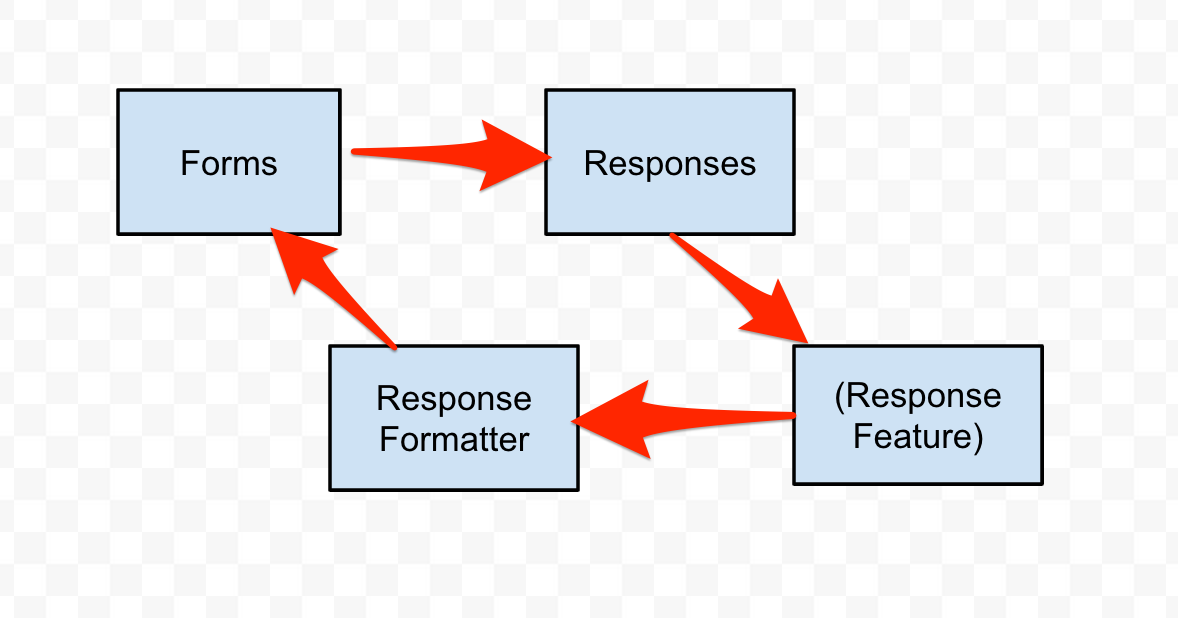
Still circular. One feature in particular connected the reponses to the formatter. What if I pull that out?
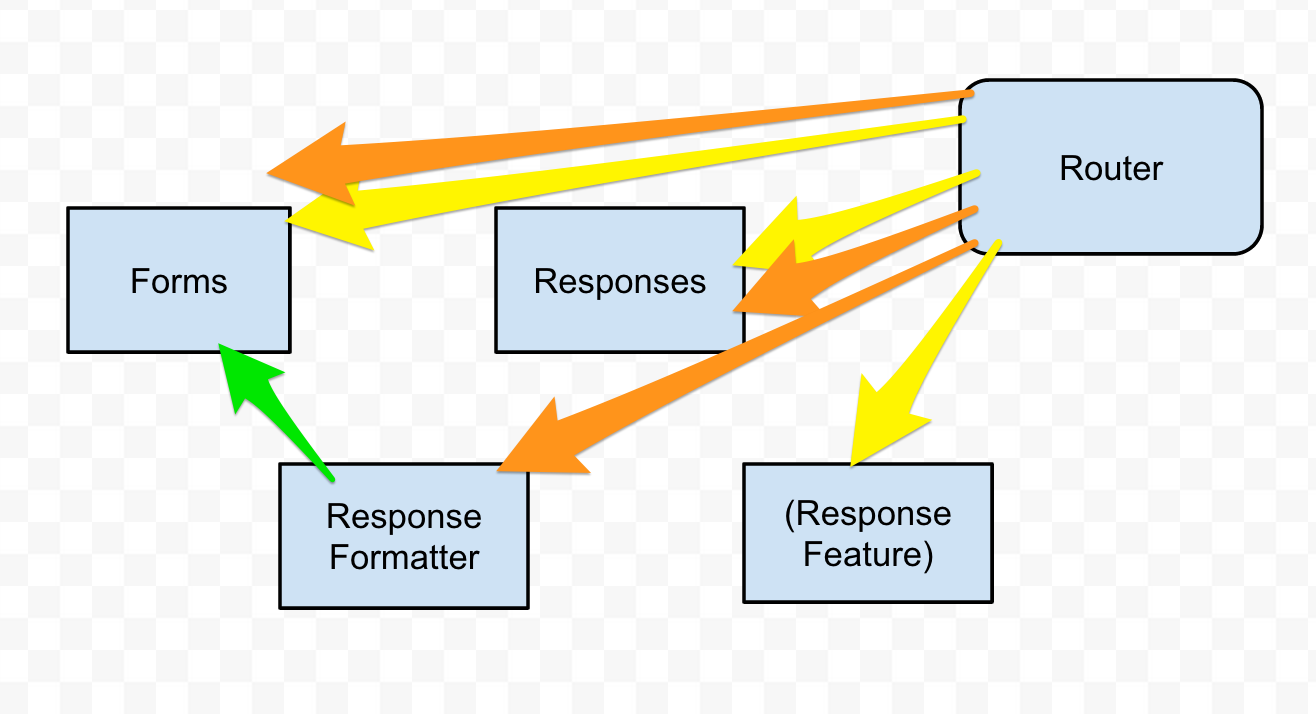
So now I have a bigger circle. That’s all I’ve been doing. I decided I needed to be orchestraing these modules’ connections from an outside place. The router made sense.
The two colors represent two different routes. It’s only doing one thing from each of the modules, but still, I don’t like having large routers.
I could make a new “manager” type module. But I’ve found that “manager” type structures just make your code that much harder to reason about. So I decided to leave it as is.
In summary, circular dependency is bad in node. Keep that in mind as you design your architecture.
I happily used javascript for a while not noting anything unique about function parameters. In most languages that I’ve worked with, function parameters are passed by value. Essentially, a copy of the variable is made and you can do whatever you want with it without worrying about messing up the original variable that’s stored safely away in the calling function.
However, it’s become evident that that isn’t always the case. Rather, sometimes, function parameters are passed by reference. This means that the calling function’s version of the variable will change as you change that variable in the callee function.
Here’s some code that shows you can change the contents of an object in a called function.
1
2
3
4
5
6
7
8
9
10
11
12
13
var myObject = {
count: 1
};
var doStuff = function(anObject) {
anObject.count++;
};
myObject.count === 1; // true
doStuff(myObject);
myObject.count === 2; // true
This was unexpected logically, but consistent with how I’ve experienced javascript. But, unfortunately, there’s more.
Only contents, not the entire object, can be changed
As Alnitak pointed out in a Stack Overflow answer, you can’t straight-up replace the object.
Here we see our original state is preserved:
1
2
3
4
5
6
7
8
9
10
11
12
13
var myObject = {
count: 1
};
var doCrazyStuff = function(anObject){
anObject = null;
};
myObject.count === 1; // true
doCrazyStuff(myObject);
myObject.count === 1; // true
This is only true for objects
Let’s look at a primitive parameter:
1
2
3
4
5
6
7
8
9
10
11
var foo = 'bar';
var doBoringStuff = function(myVar){
myVar = myVar + '!';
}
foo === 'bar'// true
doBoringStuff(foo);
foo === 'bar'// true
I don’t like really all of this, but I’m glad I have a solid understanding of how it works. If you’re going to be wanting to manipulate fields while working with the “conventional” understanding of “pass by value”, then I would recommend lodash’s clone and cloneDeep methods.
When using the method of nesting tests as described here, the final syntax becomes a little different. (Note that I’ve also set the environment variable).
1
NODE_ENV="test" istanbul cover -x='public/**' --include-all-sources _mocha $(find test/tests -name'*.js')
The _mocha is what the mocha command uses at a deeper level. The code needs to be run with this executable. See their GH for more info.
A coverage directory is created by Istanbul. This directory contains the results of your tests including a nicely formatted HTML report.
To open that up we can type:
1
$ open coverage/lcov-report/index.html
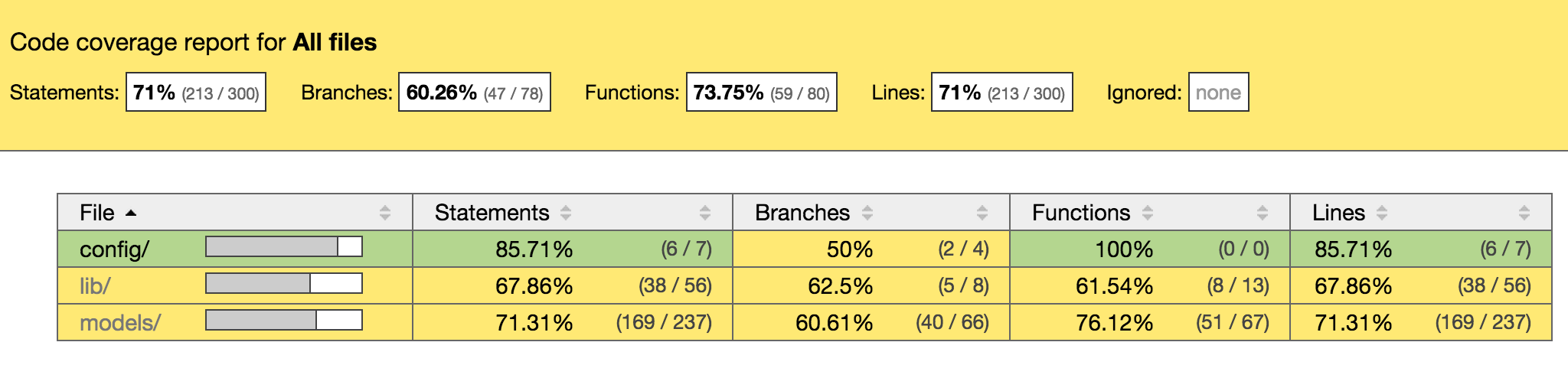
Here’s a sample view of what pulls up in my browser:
I could probably ignore the config directory :| We can do that with a modified command:
1
$ istanbul cover -x "config/*" _mocha
You can click any of the folders to drill down and see all the files.
Note: Only files that are pulled into the test suite are examined and included in the results. If you leave files completely untested, your results will not be accurate.
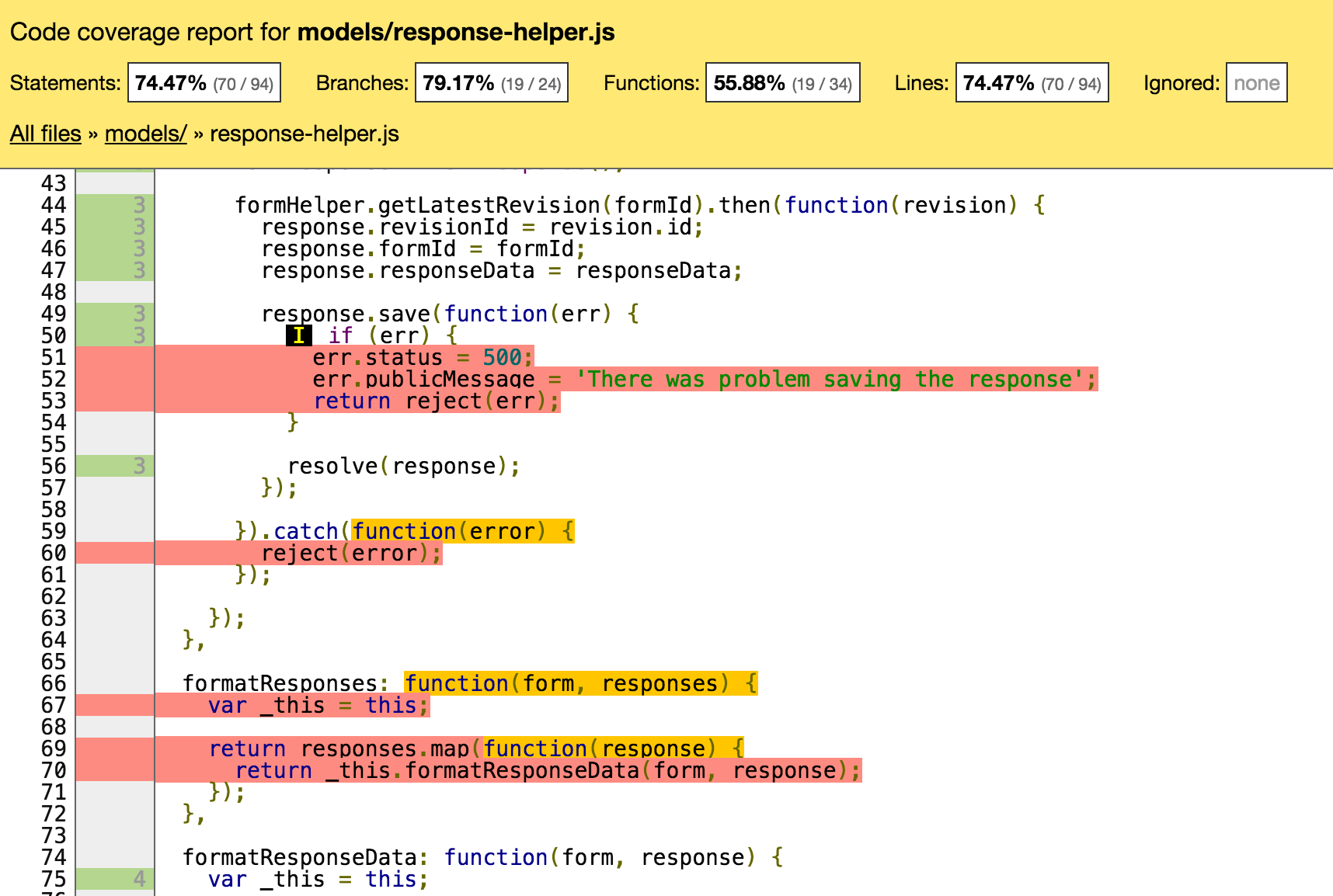
You can ultimately drill down into each file too. Here’s a view:
We can see what never occurs in my tests. We see a couple code branches that never get tested. We also see that an entire function is not tested.
Form submissions. You know what those are. What if the form changes?
Here’s my dilemma. What if a user changes/removes a field? What should be their experience when looking at old responses.
TL;DR There are a lot of scenarios and use-cases. You should have the flexibility to show the response with the form schema that was used to generate the response. If you store your data so that data is never orphaned or misrepresented later, you have flexibility and there’s less confusion when examining your data.
Three scenarios
1. User no longer wants a field
Best case scenario, I feel like I can hide or show old data. At this point who cares?
Conclusion
My thought is that, if the user doesn’t care, we shouldn’t show the old data. Scenario 3 address the case where the user does care.
2. User edits a field
Let’s say a user changes the “value” of some checkbox… say from “blue” to “cerulean” (A more specific color)? If I’m viewing old responses, should I update “blue” to “cerulean”… as the value… as just the label?
Initial thoughts
I feel like if a user is editing a field, they are fixing the field. Therefore, I am free to label all previous responses with the new updated value. In my years of experience, seeing similar values (e.g. “first name” and “firstname”) that remain unreconciled is an annoyance.
Concerns
The concern here is that the user treats the editing of a no-longer-desired field as a way to “efficiently” delete and create a new field. If labels are updated to reflect the change, then that could lead to confusing problems.
Conlusion
I feel like a user can learn from updates for the sake of consistent data. They would discover the updates quickly.
3. User removes a field, and adds a new field meant to replace the old field
This is the case where a user could edit but chooses not to. Or, this could arise if the user wants to update a field. Say they originally create a standard “text” field but then want to change it to a “number” field…. or even a “textarea”.
Concerns
This case is logically different than the case when a user simply removes an unwanted field, but, it is techincally the same. Let’s pretend that the user removes a desired field from a mature form (lots of responses).
What can be done?
We can convert fields
At this point, there’s no 100% reliable way to passively reconcile historical data. We could never be certain, even if the names were the same. What does converion look like? In my case, this would mean going through the repsonses and updating the old field ID to the new field ID. This, of course, would be in response to the user acting upon some exposed option to convert the field.
This seems ok. But…
What if we want to re-render the old field (perhaps to edit)? We’d need to change other properties in the old response (most notably the field type).
What if the old value doesn’t match approved new values? For example, what if we switch from a “text” field to a “select” field. Furthermore, I’m storing the answer of such fields with options as “IDs” instead of text representation. This generally makes it much harder to reconcile historic responses since we’d have to first find the ID of the matching text option. And if there is no match? Then what? If we leave the answer as-is, not we have some answers containing IDs, and other answers containing strings.
This is complicated stuff. Do-able, but complicated. If we take re-conciliation off the table, what can we do?
Do nothing
While the user did delete the field, I feel like they would be pretty upset to have access to old data blocked.
Show old fields in form responses
Currently, I’m showing the current form labels then showing the repsonse (if it exists). Old data is hidden. I could continue to do that, but also add the old label and value below. In my case, this means refactoring to store the old label with responses. Right now I just store IDs in responses.
My responses and my forms are tightly coupled. It seems like a waste to essentially store the form schema with every response (which is why I didn’t). I suppose I could store each revision of the form and then mark the revision in the response. I would be storing more forms… but it’s still fewer bytes in most cases. (e.g. 5 revisions of forms with 100 responses compared with 1 form with 100 reponses each containing a lot of details about the 1 form). Both of these options would undermine my conclusion about scenario 2 though :( I’m ok with that… I think.
Conclusions
See the next scenario :)
The user deletes a field. Later, they want to see data about that field.
This is similar to the previous case. The difference is that “conversion” wouldn’t help you here. This leaves the option of showing old fields in the form response. This helps re-inforce that showing old fields is really the first step in a robust form response archive.
Now what?
Well, now I know that being able to show old form responses is the minimum viable solution to this problem. This, however, means I need to re-factor :|
Re-factor follow up
I solved this problem by treating each form model as a revision. The response data points to the revision. All revisions of the form share a common formId property, which is a new property. I also have a new boolean propety called latest on the most recent revision. I could do timestamp stuff, but I like that that property is there.
What principles can I take away from this?
Don’t link two sets of data in a way that one set of data can have orphaned peices of data. This leads to confusion, wasted data, and limits options.
Don’t store your data in a way that opens wide the doors for an illegitmate represenation of the original data’s intent (e.g. Checkbox value changes from “yes” to “no” because of a form field schema edit… we should be able to reconstruct the original “yes” value).
I’ve found it effective to set global variables on the global object in a beforeEach hook.
1
2
3
4
beforeEach(function() {
global.myVar: 'foo';
global.mySecondVar: 'bar';
});
If your variables are common across tests, you can stick that in a global file.
The beforeEach, I think, is almost always a better call than before. With before, the variables are established one time. After that, the state of those variables can be modified by methods in your codebase! You might notice this when tests pass in a single file, but not when the whole suite is run. beforeEach resets them for each test.
Thinky is a wonderful ORM for rethink DB. The docuementation is generally good but I couldn’t find a way to simply get all records from a single table.
I was thinking the answer should be something like:
1
2
3
MyModel.all().run().then(function(results) {
// ...
});
However, the all() isn’t a thing. The answer is simply to just execute the run().
1
2
3
MyModel.run().then(function(results) {
// ...
});
The rethinkdb syntax for the same query is similar so this behavior makes sense.