(not including Command + F or Command + Shift + F)
10. Command + 1
Show/hide the Project Tab
9. Option + up arrow
Selects word at cursor position. Keep hitting the up arrow to increase scope.
8. Option + Shift + up (or down)
Move the current line up or down instead of using copy and paste.
7. Shift then Shift (double tap)
Brings up a menu to search EVERYTHING. But it also brings up recent files you’ve worked on. Helps you go back and forth between files you’ve looked at recently. This feature is also available via Command + E
6. Command + Shift + N
Make a new scratch file (temporary file) if you just need to paste some stuff. You can get syntax highlighting in it as well.
5. Command + L
Go to line
4. Option + F1 (then Enter to select the first item)
Scrolls to the current file inside the Project view (Alternatively, in the Project view “settings” (the cog wheel at the top) you can select “Autoscroll from source” then the Project view will always move to the active editor.
3. Command + Shift + A
Opens up the action search menu. Just type what you want to do and magic happens. Want to show whitespace for a file? Type “whitespace”. Want convert tabs to spaces? Type “To Spaces”. Want to convert double quotes to single quotes? Type “quote”. Want a quick peek at the git history? Type “annotate” (Like Command + Shift + P on Sublime or VSCode but way more stuff baked in without plugins)
2. Control + G
Selects the next instance and adds a new cursor (like Command + D on Sublime or VSCode)
1. Command + Shift + O
Search for a file by name (like Command + P on Sublime or VSCode). Some varians include Command + 0 to search classnames and Command + Option + O to search symbols.
BONUS: A couple plugins I like:
The “Open in Git Host plugin” opens Github to the current line/file… useful for sharing links. For whatever reason the native handling of that in IntelliJ is disabled for me. https://plugins.jetbrains.com/plugin/8183-open-in-git-host
Unit testing in Angular can be tricky because of the digest cycle. Your test code might have multiple references to $scope.apply(); in order to get promises moving.
Recently I was testing something that happened after a $timeout(). In the unit test file, I was unable to see the results that I expected. I tried $scope.apply() but that didn’t do anything.
Making sense of Laravel Service Providers and Service Containers
I’ve read the service provider docs several times and I was always left with a vague understanding. Maybe a new explanation will be helpful? Here goes.
10,000 foot view
Laravel’s service providers are a little more than, but very much concerned with the concept of dependency injection. Here’s a non-academic description of dependency injection:
Dependency injection is sticking a required value in the parameter of a constructor or a setter method.
If a dependency that you’re injecting is simple has no dependencies of itself, this is no problem. But sometimes, your dependencies need a more hands-on approach to their instantiation.
The service container is where you would put the rules for making an instance of class that is being auto-loaded.
The service provider is a place where you can put the service container code.
In the above code we have a class whose constructor expects a FaceService object. Our use statement above shows where it’s located. Because Laravel is awesome, it will autoload the FaceService class.
In many cases, this works great, but if we try to use our code, we will see this error: Unresolvable dependency resolving [Parameter #0 [ <required> $apiKey ]] in class App\Services\FaceService
Why?
The FaceService has specific dependencies of its own. This is why we need to use the Service Container.
Here’s the constructor of the face service.
1
2
3
4
publicfunction__construct($apiKey)
{
$this->apiKey = $apiKey;
}
So our dependency is an api key. It could be anything… another object… whatever. But if we inject this FaceServcice depency into our controller, we need to ensure that the FaceService is able to be instantiated correctly.
That’s where the Service Container comes into play.
The Service Container helps us set up our dependency
The above code says that when App\Services\FaceService is going to be auto-loaded…. do stuff. In our case, we want to instantiate a new FaceService object with our API key.
Since the first parameter in the bind method is a string, you can’t use the short version of the classname. You gotta send the whole path a la App\Services\FaceService.
Now by binding to the service container, Laravel knows how to auto-load FaceService.
This code lives in the Service Provider
You saw the Service Container code above but I didn’t say where to put it. It goes in a Service Provider. And specifically, it goes into the register mehod.
You can create a new Service Provider by copying an existing one or using php artisan make:provider ProviderName
The above code contains our code that binds to the service containe, it’s wrapped nicely inside the register method.
Finally, tell Laravel about the provider
The final thing we need to do is tell Laravel about the Service Provider. To do that we need to add to the providers array in config/app.php. Like so: App\Providers\FaceServiceProvider::class,
That’s it.
Conclusion
We now can see that the Service Container lets us define rules for how classes are auto-loaded during the dependency injection process. The Service Container code lives inside the Service Provider class, which must be registered in config/app.php
The Service Provider does more than just do this type of registration, but this is a good starting point.
Notice that nobody has permission to execute the script. We need to add that in. So I added deployment task (in capistrano) to make the script executable.
My favorite thing about JSPM was running through the documentation and everything just worked!
I chose it because of the way that it handled all the different ways of module dependency for you. This worked with modules from NPM or even direct from github.
Development was also easy. System.js took care of all the loading on every page. I didn’t need to build anything, setup gulp rules. It just worked. During deployment, you would issue a single command on your production server and it would package evertything up and, in some sort of wizardry, would insert it into your app for you. For someone who doesn’t have much patience for learning the intracacies of build systems and settings, this was perfect.
Why I’m leaving
Once bundled, my project is fast and responsive, but while in dev mode it’s unberably slow. Every single file is requeststed on a fresh page load. If you’re building a React app and modularizing as much as possible, this leads to hundreds of requests. This takes time. About 15 seconds. On every page load.
I dove into the mega threads on github. I upgraded to beta versions of JSPM, but nothing made much of a dent.
I would still consider JSPM for smaller projects and maybe this will all get resolved, but for now, here’s my path forward.
First thoughts
After reading up on webpack, it became clear that the flow is very different from JSPM. JSPM (or more accurately system.js) essentially (from my perspective) builds a bundle in the browser as it loads. With Webpack, we will need to build our bundle explicitly whenever we change code, and then link to that bundle on our webpage. To build the bundle, we need use webpack on the command line to do so. Fortunately, webpack has a watch mode that can quickly make bundles do to caching unchanged modules.
Initial setup
Our requirements are quite simple. I want to run a react app and make use of es6 features by using Babel.
The first step is to install webpack globally: npm install -g webpack.
…and the the dependencies we need: npm install --save-dev babel-loader babel-core babel-preset-es2015 babel-preset-react json-loader
The last two are the presets that allow us to parse es6 and JSX files.
The second step is to create our config file. It should be called webpack.config.js and live in the root of your project. This is mine:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
module.exports = {
entry: './main.js',
output: {
filename: 'bundle.js'
},
module: {
loaders: [
{
test: /\.jsx?$/,
loader: 'babel-loader',
query: {
presets: ['es2015', 'react']
}
},
{
test: /\.json$/,
loader: 'json',
}
]
},
resolve: {
extensions: ['', '.js', '.jsx']
}
};
Config Gotchas
JSX and JS loading
There are a couple gotchas. In JSPM land, I was using the .jsx suffix for all my JSX files. JSX kept failing to be parsed. I would get Module build failed: SyntaxError .... unexpected token. Of course all the search results say to use the babel-preset-react. What I didn’t realize is that in the module.loaders config value, my regular expression was only for .js files. If we use /\.jsx?$/ then that will work for both .js and .jsx files.
JSON errors
Secondly, I ran into module parse errors loading .json files. For this we need that second object in the module.loaders collection that connects json files with the json-loader package.
Fix as you go
Now for the hard part. With a decent, albeit basic, webpack config file in place, we can run webpack at the root of our directory to get our build. You’ll probably get some errors. The only way forward is to fix them as they come up.
Fix as you go Gothchas
My main strategy was to try and get the webpack command compiling. Once that was working, I would use the webpack --watch command as I messed with code changes. But I actually had a difficult time getting the --watch option to work. As I was hacking all this out I was doing plenty of npm installs and npm uninstalls. At one point I uninstalled some dependencies. So if you get a Module not found error on a 3rd party module, try re-installing all the packages you know that you need (including webpack!)
Filenames
I ran into errors finding.jsx files. I would get a webpack error saying mymodule.jsx not found. If you refer back to the config file, the resolve entry has the .jsx extension so we are able to refer to the modules without explicitely including the .jsx extension.
So my first code change was to change my import statements to not use the .jsx extension. For example, I changed:
1
import MySubModule from'./my-sub-module.jsx!';
to
1
import MySubModule from'./my-sub-module';
I like this change a lot! I just did a find and replace in bulk.
Packages
I basically went through my config.js file used by JSPM to see what the package situation was. For all the dependencies that are in NPM, the fix is simple. Just npm install each of those packages. Webpack will find them from there.
Nodelibs
A lot of my non-NPM dependencies were node libs installed by JSPM via Github. For example, in the config, there is an entry (and a ton of similar ones) for:
1
2
3
"github:jspm/nodelibs-events@0.1.1": {
"events": "npm:events@1.0.2"
},
The solution was to replace these with an appropriate NPM module. In the case of the above, we replaces the JSPM version with the events package.
1
import events from'nodelibs/events';
had to be changed to:
1
import events from'events';
Of course, imports of other node libs would need similar code changes.
Script inclusion
None of this matters if we don’t include the code! In our HTML pages we need to replace the familiar system.js inclusion code:
1
2
3
4
5
<scriptsrc="/jspm_packages/system.js"></script>
<scriptsrc="/config.js"></script>
<script>
System.import('js/main');
</script>
with a more standard inclusion of our bundle. Refer to your config file to see where this file will be.
1
<scriptsrc="/build/bundle.js"></script>
Deployment
The deployment is quite similar. Running webpack from the command line or via a deployment script is all it takes to generate the same bundle file that you’ve been using in development. Heck, you could even include the built bundle in your repo and be done with it. Which if you read below… has a (uncomfortable) place.
Deployment Gothchas
My production server doesn’t have much memory. So moving all the packages to NPM caused some problems. The use of JSPM splits up the deployment workload because NPM runs and then JSPM runs later. However, with webpack NPM is the star of the show. I was having trouble getting my npm install --production to finish without crashing due to a lack of memory. My solution (not a good one) was to mark the dependencies for webpack (including all the babel stuff above) as dev dependencies by modifying the package.json file to move those package names under devDependencies.
1
2
3
4
5
6
"devDependencies": {
"babel": "^6.5.2",
"babel-core": "^6.10.4",
"babel-loader": "^6.2.4",
"babel-preset-es2015": "^6.9.0",
"babel-preset-react": "^6
Dev dependencies are not installed when the production flag is used with npm install If we include our bundle.js file in the repository we have no need to do any webpacking on the production server, since it will already be bundled.
This strategy is generally frowned upon, but it makes the NPM install process shorter and less memory intensive. I didn’t go so far as to isolate packages I only use on the client as dev dependencies since I hope to upgrade my servers at some point and don’t want to go too far off the beaten path. I plan to revert this change some day.
Dev-ing
Now that we have webpack in place, we can use webpack --watch while we work and all our JS updates are bundled at every change. But don’t worry, it’s very fast since it caches unchanged modules in this mode.
Next Steps
Webpack has a development server built-in. I still am using gulp for sass and browser-sync which is why I haven’t used the development server. But I know sass and browser-sync are both options that can be added onto webpack. I will investigate that.
Webpack also provides this cool feature of multiple entry points. Here is a good description of that. I think moving forward I will try to take advantage of that feature.
At the top of a newly generated express app using express’s application generator you’ll see one of the bundled dependencies:
1
var logger = require('morgan');
Later we see it initialized with the other middleware like:
1
app.use(logger('dev'));
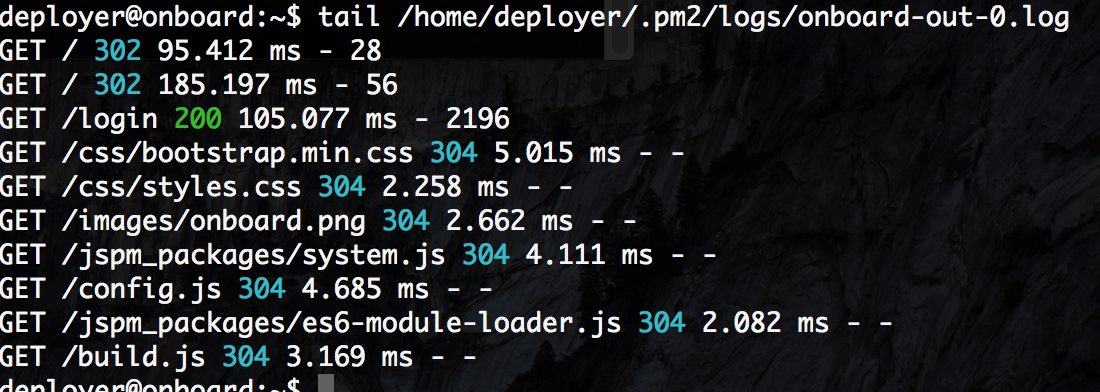
Here is the output that is produced:
Now, in a hurry to get my code out and on the web I never paid close attention to what was happening. The ‘dev’ aspect just went right over my head. When bugs crept up in production, the log files were very difficult to utilize since there wasn’t much information. Specifically, there is no date and no way to tell who is making each request.
If we simply look at the Morgan documentation we will see many useful pre-defined formats. I like the combined setting becuause it provides user agent info. In my stint in customer support, identifying user agents has been helpful.
We can make our change like this:
1
2
3
4
5
if (app.get('env') === 'production') {
app.use(logger('combined'));
} else {
app.use(logger('dev'));
}
Let’s look at our logs now:
Lots more info! But… if you look closely, you’ll see the IP address looks awfully useless. I’m running a reverse proxy setup with NGINX to serve my site, so it actually makes sense that the IP addresses would all be internal. We need a way to get at the source IP address.
Configure NGINX to forward the real IP address
To do this we need to update the location block in our site configuration file in the sites-available directory.
1
proxy_set_header X-Forwarded-For $remote_addr;
And then of course we’ll need to restart NGINX (sudo service nginx restart).
Tell Express to use the remote IP address
In the Express proxy documentation we can see how to take advantage or our newly forwarded IP address. By enabling the trust proxy feature, the IP address will be updated in the correct places with the forwarded IP. It will also be available on the req object. We can enable the trust proxy feature after initializing the app.
1
2
var app = express();
app.set('trust proxy', true);
The final result:
We now have IP addresses. No we can see dates, IP addresses, user agents and lots more when looking through our logs.
When we had our first beta user give us a heavy load, we ran into some issues. In this instance, we were using RabbitMQ to communicate with our text messaging service. In our testing, we never had any problem with missed text messages, but we started hearing reports of text messages never getting delivered or received.
Now, I’ve seen blog posts saying that can crank a million messages a second out of RabbitMQ. I know you need to be a pro to do stuff like that, but it never occured to me that our level of usage thus far (a couple hundred spread out over a minute or two) would ever cause a problem. But, after not finding any issues in the surrounding logic, I decided to test RabbitMQ.
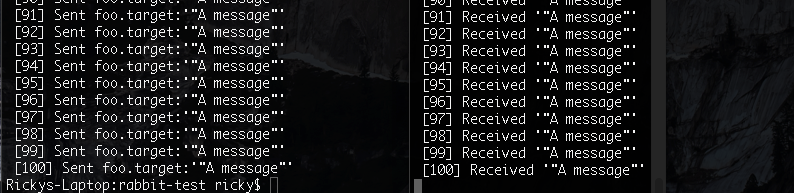
channel.publish(exchange, key, new Buffer(message));
console.log(" [" + count + "] Sent %s:'%s'", key, message);
};
preSend().then(function(cc) {
for (var i = 0; i < 300; i++) {
send(cc.channel, 'hi there', 'foo.target');
}
cc.channel.close().then(function() {
cc.conn.close().then(function() {
console.log('TX complete');
});
});
});
All the message made it! But I don’t like this pattern. My messaging is sporatic. Do I want to deal with the overhead of managing the connection? Maybe? Probably? But not now.
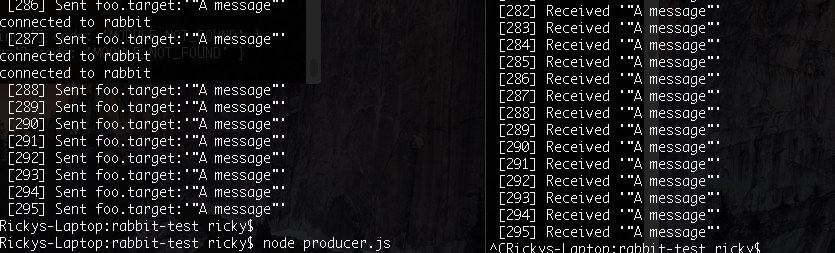
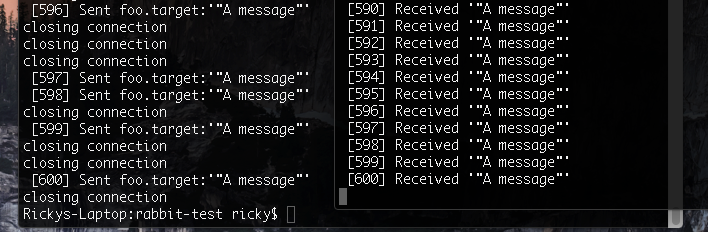
What if I just resend on a failed connection
Simple, I like it! But we need to be able to see if our message was successfully sent off. To do that we use ConfirmChannel
It basically means that instead of createChannel, we use createConfirmChannel. The server will then acknowledge our message when we issue the publish command. If it doesn’t we can schedule a resend. There’s some extra code in there to create a little space and potentially give up, but so far everything works well.
I’ve barely scratched the surface with how make RabbitMQ rock solid, but since I have implemented these changes, we have had no more complaints about messages getting through.
I would like to learn more about the cost of opening so many connections at once. It may be worth it to better manage my messages as our load increases.
Another next step is that, instead of giving up, we can store the message in a database for re-sending at a later time.
Moment.js is a javascript library that makes working with dates and times way easier than using native javascript methods. It’s worth its weight in gold.
That said, I’ve ran into some areas that haven’t been intuitive for me.
Manipulating moments
Let’s look at the following code:
1
2
3
var start = moment();
var startPlus1 = start.add('1', 'hours');
var startPlus3 = start.add('3', 'hours');
I expect the three values to be different. However, they are all the same and they all equal start + 4 hours.
Moment’s add method doesn’t return a new object. Rather it manipulates the given object. From another post, we can see that simply making a new variable isn’t a true separate copy of the object.
The workaround is quite simple. We can create a new moment from an old one.
1
2
var startPlus1 = moment(start).add('1', 'hours');
var startPlus3 = moment(start).add('3', 'hours');
Now are moments are all different and as expected.
Timezones
I was just about at peace thinking that I couldn’t work in any timezones other than local or UTC. And by “work”, I don’t mean simply displaying the time in the correct timezone. I mean, manipulating moments with functions like startOf and endOf.
As I write this it is 9:48am pacific time.
1
2
3
4
5
var start = moment().utcOffset(-5);
console.log(start.toDate());
// Output
Fri Aug 07201509:48:15 GMT-0700 (PDT)
What I expected was Fri Aug 07 2015 09:48:15 GMT-0500 (CDT) Another expectation was Fri Aug 07 2015 07:48:15 GMT-0700 (PDT) I did not expect the current time. The utcOffset method appers to do nothing.
But what if we use moment’s formatting capabilites?
1
2
3
4
5
6
7
var start = moment('2015-08-05 10:00:00').utcOffset(-5);
console.log(start.toDate());
console.log(start.format('MM/DD/YYYY H:mm:ss'));
// Output
Wed Aug 05201510:00:00 GMT-0700 (PDT)
08/05/201512:00:00
The times are different. 10am pacific it certainly not noon. The difference is that the formatted time has been backed off UTC by 5 hours… which is our CDT.
From this I conclude that Moment is storing the offset for use and not actually manipulating the underlying time. The good news is that it is getting used!
So now, if I wanted to find the start of a work day in central time, I can:
1
2
3
4
5
6
var time = moment('2015-08-05 10:00:00').utcOffset(-5);
var startOfWorkDay = moment(time).startOf('day').add(8, 'hours');
console.log(startOfWorkDay.toDate());
// Output
Wed Aug 05201506:00:00 GMT-0700 (PDT)
The first line of output shows the correct time. 6am PDT would correlate to 8am CDT. Using the same principle to get an endOfWorkDay, I can now make comparisons to see if some arbitray time is during a work day in a given timezone.
The last piece is to be careful about how I get my offset. The timezone offsets are not consistent primarily due to daylight savings times. That’s a topic for another day.